Table of Contents
Towards archiving & publication
This chapter in the tour guide is all about securing your research data's future for the following purposes:
- Archiving data for future reference
Research data archiving is about storing and preserving research data for the long term. When you archive your data, you make sure you can read and access the data later on. You can then also allow access to others for verification purposes when such a request arrives. In all cases, you should store your data safely, in a suitable file format, with adequate documentation.
- Publishing data for reuse To make your data reusable for purposes beyond the one for which you collected them, you should publish your data. Publishing your data is the act of publicly disclosing the research data you have collected, making them findable, accessible and reusable.

The following video introduces you to the first steps towards data curation:
The incentives that motivate interviewed researchers to archive and publish their research data (Van den Eynden & Bishop, 2014; Hahnel et al., 2017) fall into four main categories:

Data publication may lead to increased visibility, reuse and citation and therefore recognition of scholarly work.
A number of studies show the impact of data publication on citation rates. Articles for which the underlying data is published are more frequently cited than articles for which this is not the case. Studies from social science (Pienta, Alter & Lyle, 2010), genetics (Piwowar and Vision, 2013; Botstein, 2010), astronomy (Henneken and Accomazzi, 2011; Dorch 2012) and oceanography (Sears 2011, Belter 2014) confirm this effect.
Be aware that whenever you use the published data you are obliged to cite them. For more information see the paragraph on data citation.
Data archiving and publication has direct benefits for the research itself (more robust), for the discipline and for science in general by enabling new collaborations, new data uses and establishing links to the next generation of researchers.
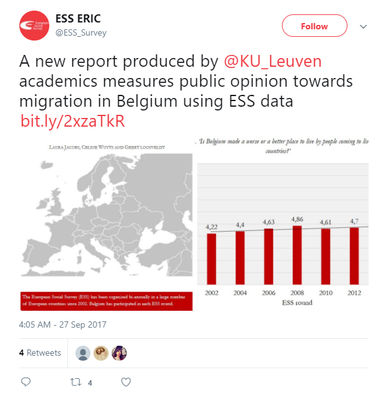
A tweet (ESS ERIC, 2017) from the European Social Survey (n.d.) is just one of the many, many examples of how sharing high-quality datasets leads towards new insights. The European Social Survey is widely accessible and used by many researchers.
Norms of the project, research group, and/or discipline may determine whether a researcher is prone to publish his/her data. Overall, the openness of research data is at the heart of scientific ethics as is illustrated by the quote below.
Sociologists make their data available after completion of the project or its major publications, except where proprietary agreements with employers, contractors, or clients preclude such accessibility or when it is impossible to share data and protect the confidentiality of the data or the anonymity of research participants (e.g., raw field notes or detailed information from ethnographic interviews) | American Sociological Association (1999).

External drivers like research data management policies from research funders and publishers have a significant influence on data archiving and publication:
- Funders
Some funders consider costs related to data archiving and publication eligible and require a DMP. For a list of funder requirements see the 'European diversity in funder requirements' section of this tour guide. - Publishers
Scientific journals are increasingly adopting data availability policies that advise or even request authors of manuscripts to make the research data, on which a manuscript is based, available. For example, PLOS One says in its data availability statement:
All data and related metadata underlying the findings reported in a submitted manuscript should be deposited in an appropriate public repository unless already provided as part of the submitted article. Repositories may be either subject-specific (where these exist) and accept specific types of structured data, or generalist repositories that accept multiple data types, such as Dryad | PLOS One (2014a).
In the coming paragraphs, the main focus will be on securing high-quality datasets for the future by combining data archiving and data publishing.