Table of Contents
File naming and folder structure
To enable you to identify, locate and use your research data files efficiently and effectively you need to think about naming your files consistently and structuring your data files in a well-structured and unambiguous folder structure.
File naming strategy

Two important starting points for your file naming strategy are:
- A file name is a principal identifier of a file
Good file names provide useful clues to the content, status and version of a file, uniquely identify a file and help in classifying and sorting files. File names that reflect the file content also facilitate searching and discovering files. In collaborative research, it is essential to keep track of changes and edits to files via the file name. - File naming strategy should be consistent in time and among different people
In both quantitative and qualitative research file naming should be systematic and consistent across all files in the study. A group of cooperating researchers should follow the same file naming strategy and file names should be independent of the location of the file on a computer.
In the tabs, a best practice and examples of useful file names are given.

Several aspects of naming that are particularly important for qualitative data (Finnish Social Science Data Archive, 2016):
- If you have large numbers of files of different types, you should produce a document describing the file naming convention used for the research;
- Background information about each item (individual interview, focus group, photograph etc.) is usually indicated in the file names. Nevertheless, you should always present background information in separate documents.
Consistency of naming
The benefit of consistent naming of data files is that it is easier to identify all files connected to one data collection event (e.g. one interview). The files related to one collection event (e.g. audio tape, its transcription and photographs that were taken by the interviewee) can be connected by the file name.
The most convenient way is to give all files connected to the same event an 'event identifier' in the beginning of the name, that is, in the first part of the name. The latter part of the name can be used to convey the specifics, for instance, whether it is an audio tape, transcription or a still image:
Example:
- 20130311_interview2_audio.wav
- 20130311_interview2_trans.rtf
- 20130311_interview2_image.jpg
Documenting data file conventions
An example of how to document the data file conventions you use:
<date><type><ID1><gender><age><municipality><datatype><ID2>
where:
- <date>is the date on which the data were collected (date format should be YYYY-MM-DD);
- <type> specifies the type of event/data material;
- <ID1> is the ID of the collection event;
- <gender> is the gender of the interviewee;
- <age> is the age of the interviewee;
- <municipality> is the municipality of residence of the interviewee;
- <datatype> specifies the type of data the file contains, for instance, "trans" means transcription, "audio" means audio recording, and "image" means photograph;
- <ID2> is the ID number used to separate the images connected to the collection event.
Folder structure
Structuring your data files in folders is important for making it easier to locate and organise files and versions. A proper folder structure is especially needed when collaborating with others.
The decision on how to organise your data files depends on the plan and organisation of the study. All material relevant to the data should be entered into the data folders, including detailed information on the data collection and data processing procedures.
Consider the best hierarchy of your files and decide whether a deep or shallow hierarchy is preferable. If you have several independent data collections, it is advisable to create a separate data folder for each collection. For inspiration, have a look at the examples in the accordion below.
For this survey, data and documentation files are held in separate folders. Data files are further organised according to data type and then according to research activity. Documentation files are organised also according to the type of documentation file and research activity. It helps to restrict the level of folders to three or four deep and not to have more than ten items on each list.
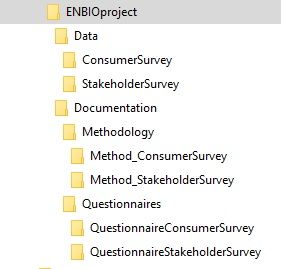
In this example, the data contain audiotapes of the interviews, interview transcripts, stimulation material shown to the research subjects, and photographs taken by the subjects. Data files are files connected to the same interview event conducted on the 22nd of January 2013. The latter part of the name reveals the specifics of the file. In this case, "audio" means audio tape and "trans" a transcription of the audio tape. However, background information must never be stored in the file name only.
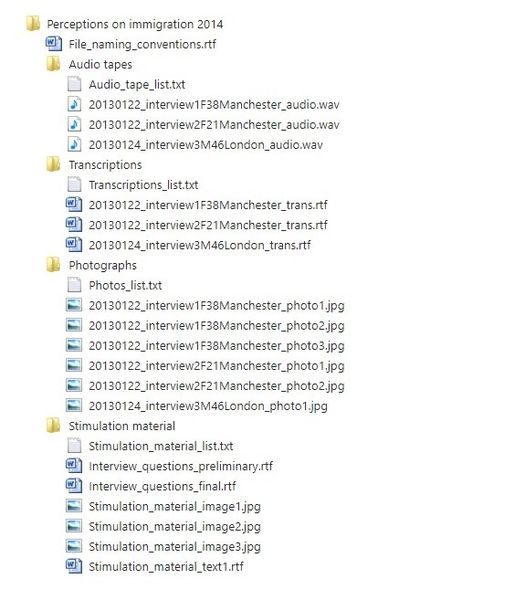
This example was taken from UK Data Service (n.d.b).
TIP: Batch renaming of automatically generated files

Batch renaming is organising research data files and folders in a consistent and automated way with software tools (also known as mass file renaming, bulk renaming).
Batch renaming software exists for most operating systems. See the accordion for examples.
It may be useful to rename files in a batch when:
- Images from digital cameras are automatically assigned base filenames consisting of sequential numbers;
- Proprietary software or instrumentation generate crude, default or multiple filenames;
- Files are transferred from a system that supports spaces and/or non-English characters in filenames to one that doesn't (or vice versa). Batch renaming software can be used to substitute such characters with acceptable ones.
How to ... use Bulk Rename UtilityFollow the steps in the video to use Bulk Rename Utility to batch rename your files. |