Table of Contents
Documentation and metadata

I have never documented my data before. I have both qualitative and quantitative data and I work on a collaborative project. Where do I start?
What is metadata and how do I document my data?
Start getting familiar with metadata by watching this video: Alexander Jedinger discusses metadata and data documentation. (This video is also available on Zenodo)
Please this video cite as: Jedinger, Alexander. (2020). What Is Metadata and How Do I Document My Data?. Presented at the CESSDA Training Days 2019 (CTD2019), Cologne, Germany: Zenodo. http://doi.org/10.5281/zenodo.3923956
Systematically documented research data is the key to making the data publishable, discoverable, citable and reusable. Clear and detailed documentation improve the overall data quality. It is vital to document both the study for which the data has been collected and the data itself. These two levels of documentation are called project-level and data-level documentation.
Project-level documentation

The project-level documentation explains the aims of the study, what the research questions/hypotheses are, what methodologies were being used, what instruments and measures were being used, etc. In the accordion the questions that your project-level documentation should answer are stated in more detail:
Data-level documentation

Data-level or object-level documentation provides information at the level of individual objects such as pictures or interview transcripts or variables in a database. You can embed data-level information in data files. For example, in interviews, it is best to write down the contextual and descriptive information about each interview at the beginning of each file, and for quantitative data, variable and value names can be embedded within the data file itself.

Variable-level annotation should be embedded within a data file itself. If you need to compile an extensive variable level documentation, you can create it by using a structured metadata format.
Data-level documentation for quantitative data
For quantitative data document the following information is needed:
- Information about the data file
Data type, file type, and format, size, data processing scripts. - Information about the variables in the file
The names, labels and descriptions of variables, their values, a description of derived variables or, if applicable, frequencies, basic contingencies etc. The exact original wording of the question should also be available. Variable labels should:- Be brief with a maximum of 80 characters;
- Indicate the unit of measurement, where applicable;
- Reference the question number of a survey or questionnaire, where applicable.
- Information about the cases in the file
A specification of each case (units of research like e.g. a respondent) if applicable. - Names, labels and descriptions for variables, records and their values
- Description of the missing values at each variable
- Description of the weighting variable
- Explanation or definition of codes and classification schemes used
Storing documentation
Whenever possible, embed data documentation within a file. Click on the accordion for an example.
In this example from the UK Data Service (n.d.c), you see two SPSS tabs: Data view and Variable view, the tab which is visible right now.
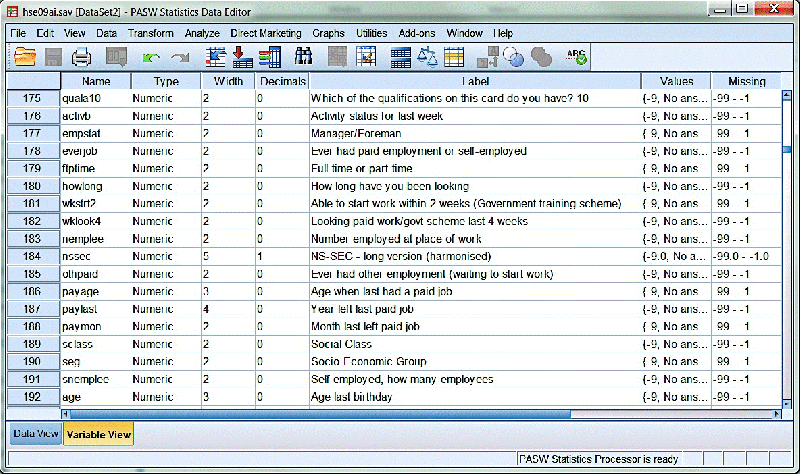

Background and contextual information and participant details of interviews, observations or diaries can be described at the beginning of a file as a header or summary page.
Data-level documentation for qualitative data
For qualitative data document the following information is needed:
- Textual data file (for example, interview)
- Key information of participants such as age, gender, occupation, location, relevant contextual information);
- For qualitative data collections (for example image or interview collections) you may wish to provide a data list that provides information that enables the identifying and locating of relevant items within a data collection:
- The list contains key biographical characteristics and thematic features of participants such as age, gender, occupation or location, and identifying details of the data items;
- For image collections, the list holds key features for each item;
- The list is created from an initial list of interviews, field notes or other materials provided by the data depositor.
- Audiovisual data files
For some types of data (image, audio or video files) the file format does not always allow recording background information in the beginning of the data file. In such cases, the best practice is to store background information in a manually created data list or a separate text file: a data list which accompanies the data collection.- Provide the following information on each image: creator, date, location, subject, content, copyright, keywords, equipment used;
- Some image files have embedded technical metadata (You may use tools to extract technical metadata from images, such as ExtractMetadata.com (n.d.)).
In this case - shown on the site of the Finnish Social Science Data Archive (2016) - the background data fields are manually entered in table form using Excel (or Open Office Calc program). The data collected were video-recorded interviews. The data list contains background information related to the interviewee and the interview event as well as information on the model and brand of the camera used and the length of the video (in minutes).
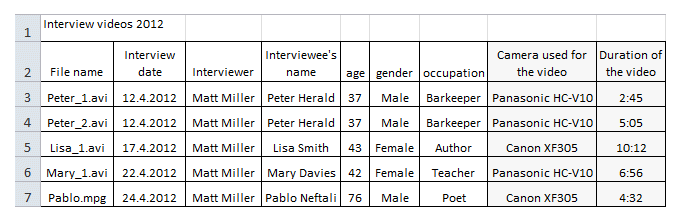
See also another data list example from the UK Data Service (n.d.c).
- Periodicals, magazines, journal articles
Among materials you use for qualitative data analysis, there may be online periodicals, magazines or journal articles. The information about all such resources must be kept in separate files:- Material collected from online periodicals: save references to web resources, like URLs, and do not forget they may change over time. To be sure information is not lost, articles should be copied into a word processing program;
- Materials from periodicals: When articles, photographs and other material are collected from periodicals for research purposes, bibliographic information should be carefully detailed (author(s), title, date of publication etc.);
- When you analyse articles, make a list of them, sort them alphabetically or chronologically in the order they were analysed in the course of research.
Storing documentation
- Write the documentation into a separate, well-structured file, and associate that with the data file. You may use the same filename stem in order to strengthen the file-metadata association. For example: 20130311_interviews_audio, 20130311_interviews_trans, 20130311_interviews_image, 20130311_interviews_metadata. The latter part of the name can be used to convey the specifics of the file. In this case "audio" means audio tape and "trans" a transcription of the audio tape;
- Data-level documentation can be embedded within a data file. For example, in interviews, it is best to write down the contextual and descriptive information about each interview at the beginning of each file;
- If you have a large amount of metadata or large amounts of data that will need metadata you can use a standard specific database for this purpose (such as the DDI Codebook (DDI Alliance, n.d.-a)).
Metadata: machine readable data documentation
Metadata or "data about data" are descriptors that facilitate cataloguing data and data discovery. Metadata are intended for machine-reading. When data is submitted to a trusted data repository, the archive generates machine-readable metadata. Machine-readable metadata help to explain the purpose, origin, time, location, creator(s), terms of use, and access conditions of research data.
In the tabs below we provide you with examples of:
- Metadata templates (for easy starting)
If you do not quite know yet what metadata you should generate (what fields are needed) have a look at the metadata templates provided. Some of them are very simple and can, therefore, help to create basic documentation. - Metadata standards (for when you need your metadata to be very structured).
Metadata standards may at first look seem quite scary. They are used by data archives for enhancing discoverability, interoperability and reusability. When you submit your dataset to a trusted data repository, these standards are automatically applied.
Metadata for new data types – new standards still under development
To provide metadata for social media data and transaction data with metadata, the metadata standards by the Data Documentation Initiative (DDI) should serve as the guiding framework. Importantly, however the DDI standard is "insufficient to document all the details required for reproducibility of a social media dataset" (Kinder-Kurlanda et al 2017: 3). For example, the DDI format does not allow describing biases caused by data mining interfaces of social media platforms, changes in data availability and formats, explanations about code and scripts used in collection, cleaning and analysis etc. Such information can be described only in an unstructured manner as an additional comment in the standard's form.
Together with other CESSDA partners, GESIS is currently developing recommendations for the provision of metadata for new data types (esp. social media data).