Table of Contents
Data in the social sciences
In this guide, we focus on data generated in social sciences research, both quantitative and qualitative. Notably, within the field of social sciences, you will often work with data originating from human participants. This can mean that you are handling (sensitive) personal data, which deserve special attention.
In the tabs below a definition of personal data is given and our concept of quantitative and qualitative data is introduced.
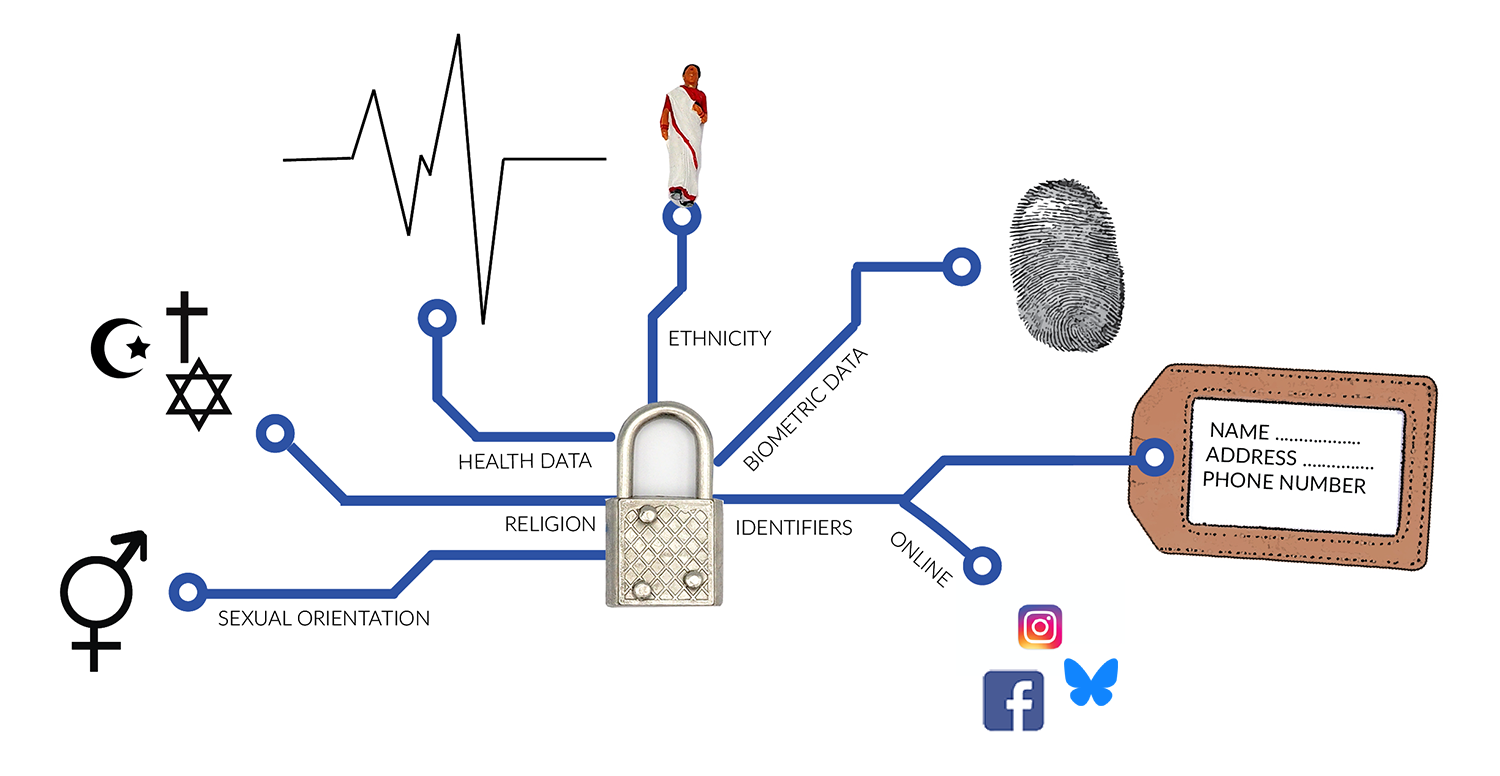
If you collect research data that enables you to identify a person, then this is classified as personal data. Within the General Data Protection Regulation (GDPR, European Union, 2016) personal data are defined as any information relating to an identified or identifiable natural person known as ‘a data subject’. It is further specified that an identifiable natural person is someone who can be identified, either directly or indirectly, by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person. Personal data can include a variety of information, such as names, addresses, phone numbers and IP addresses.
The GDPR applies only to the data of living persons. Data which do not count as personal data do not fall under data protection legislation, though there might still be ethical reasons for protecting this information.
Sensitive personal data
Certain personal data are considered particularly sensitive and thus require specific protection when they reveal information that may create important risks for the fundamental rights and freedoms of the involved individual. Examples of sensitive personal data include data revealing religion affiliation, sexual orientation, or racial or ethnic origin. Within the GDPR the following categories are defined as ‘special categories of personal data’:
- Racial or ethnic origin;
- Political opinions;
- Religious or philosophical beliefs;
- Trade union membership;
- Genetic data;
- Biometric data;
- Data concerning health;
- Data concerning a natural person's sex life or sexual orientation.
There are other data which may contain sensitive information that which does not fall under the special categories of personal data but should still be treated like as such, including, for example, confidential business data and confidential state security data.
Like with research data in general, social sciences data cover a broad range of materials, from structured numerical datasets to interviews, field notes, and documents collected for ethnographic studies, for instance. In this guide, we look at quantitative and qualitative data separately, though both can, of course, be collected during the same study. In the table below the main attributes of both types of data are shown. Even though an attribute is described in one of the columns it does not imply that it cannot exist in the other.
| Type of data |
Quantitative data |
Qualitative data |
|
|

|

|
| General description |
In quantitative research, the gathered information is in numerical form. Quantitative research is used to quantify behaviour, attitudes or opinions. The goal of quantitative research is often to test ideas stated at the start of the research, to formulate facts and uncover patterns. |
Qualitative research is primarily exploratory research. It gathers information that is not in numerical form. The goal of qualitative research is often to develop (new) ideas and a deeper understanding not achievable by numerical scores. |
| Data attributes |
Data are expressed in numbers that can be assessed using statistical analyses. |
Data are expressed in natural language, often textual or visual. |
| Data collection methods |
Quantitative data collection methods include various forms of surveys – online surveys, paper surveys, mobile surveys and kiosk surveys, face-to-face interviews, telephone interviews, website interceptors, online polls, experiments and systematic observations. In most cases it generalises results from a larger sample population. |
Qualitative data collection methods include photography, audio recordings, video, unstructured interviews, semi-structured interviews, open-ended questionnaires, diary accounts, focus groups (group discussions), individual interviews and unstructured observations. The sample size is typically smaller than quantitative samples. |
| Example dataset |
Description: Study on migrations patterns in the Summer Olympics between 1948 and 2012. The dataset covers approximately 40,000 athletes and contains information on the country they represented as well as their country of birth (open access, in English). Reference: Jansen, J. (Erasmus University Rotterdam) (2017): Foreign-born Olympic athletes 1948 - 2012. DANS. https://doi.org/10.17026/dans-2xf-pyqp |
Description: Interview with a survivor of the second world war extermination camp Sobibor (open access, in English). Reference: Leydesdorff (copyright on the interview), prof. dr. S. (Universiteit van Amsterdam - dep. of Arts, Religion and Culture); Huffener (project manager), M. (Stichting Sobibor) (2012): Project 'Long shadow of Sobibor' Survivors: Interview 01 Thomas Blatt. DANS. https://doi.org/10.17026/dans-x8h-fwjg |
(Sensitive) personal data and the guide
Tips for handling (sensitive) personal data are present throughout this guide. In particular, we would like to point out the following:
- In the chapter on storing data, you will find measures to protect (sensitive) personal data from unauthorised access with strong passwords and encryption.
- In the chapter on protecting your data, you will learn how a combination of gaining consent, anonymising data, gaining clarity over who owns the copyright of your data and controlling access to data can enable the ethical and legal sharing of (sensitive) personal data.