Table of Contents
Designing a data file structure

In an early stage of your research, you are faced with the question of what form your data files should take. Your initial decisions about the structure of your data files should be considered thoroughly.
Data file structure has a huge impact on the possible ways your files can be processed and analysed and once your structure has been filled with data, any changes to it are usually laborious and time-consuming.
File structure choice
Data files may have different internal structures and a research study may encompass several different data files in different relations to one another. The structure of the data file is also determined by the formatting of its content (e.g., types and organisation of variables). It provides information on relationships among different elements and parts of its content. An important part of the metadata is often embedded into the data file (e.g., in the form of variable names and variable and value labels, different kinds of notes and content of supplementary variables). So, the structure of your data also contributes to the clarity of your data documentation.
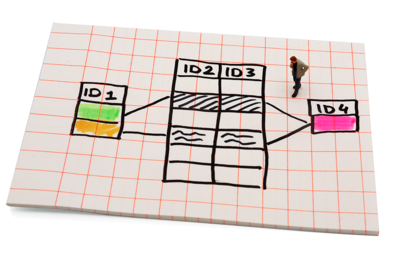
File structure choice often depends on the requirements of the software you are using, and intended analysis. At the same time, your decisions about structure may define the possibilities of future data processing, choice of software and ways of data analysis.
When deciding on a data file structure, consider the following:
- Units of analysis, possible analytical objectives and methods of analysis to be used;
- Relations
- between different content items and parts of your data file;
- to sources of your data;
- to any other relevant external data and information and their structure.
- Possibilities of building connections to other existing or future data files (future additions of new data or creation of cumulative data files);
- Possible strategies for version control (see 'Data authenticity and version control');
- Possible technical limitations, e.g., operability in relation to the size of the data file (consider that large and complicated structures may put high demands on both data management and computing capacities. Some software programs also have limitations with respect to the number of variables and cases they can manage);
- The software you are going to use (this should be done also with respect to flexibility because of possible secondary analysis of your data in other software).
Designing qualitative data files

Qualitative data files emerge from many different types of research material. Such data files are texts (transcribed interviews or focus group sessions, various types of written texts, such as newspaper and magazine material, diaries etc.) or photographs, audio files (recordings of speech) or video files. Unlike quantitative data, qualitative data are not presented in the form of variables, numbers, data matrices etc. However, they must also be organised and stored in an exact manner so they are easily managed and available for use.
Usually, individual data collection events will be structured into individual files, e.g., one interview transcript, one image, or one audio recording each time make a single file. These single files are then organised into folders of similar files. Sometimes, qualitative information may also be organised into matrix structures, e.g., textual extracts from newspaper articles or diaries may be placed into a rectangular matrix, whereby further metadata and coding can be added alongside each entry.
Designing a qualitative data structure comes down to:
- Thinking of ways to categorise data (see 'Qualitative coding');
- Developing a file naming strategy (see 'File naming and folder structure');
- Designing a comprehensive folder structure (see 'File naming and folder structure').
Designing quantitative data files

In quantitative research, the content of the data often results from numerical coding in standardised questionnaires (see 'Quantitative coding'). In addition, full-text answers or textual codes can be recorded into specific types of variables in quantitative data files. Quantitative researchers may also store other material, i.e. administrative data, data from social media or various texts. In this chapter, however, when we speak about quantitative data, we usually mean survey data.
In the accordion below you will find a description of three types of file structures - flat, hierarchical and relational - which are commonplace in quantitative social science. Also, two examples which clarify the concepts are presented below.
| Description |
File types |
| Flat (rectangular) data files are organised in long rows, variable by variable. One row is dedicated to one subject of observation and/or analysis. An ID number usually comes first. If variable values are organised column by column, we obtain a rectangular matrix. |
SPSS and STATA and similar software are often used for analysing flat files. Here the structure consists of one rectangular matrix with data, accompanied by variable and value labels. In this case, each record includes the same amount of information and has the same length as all other records in the data file. If the variable is not applicable for a particular observation, it is filled with blank spaces or missing values. |
| Description |
File types |
| Hierarchical files consist of higher-order and lower-order records which are arranged in a hierarchical structure, i.e. several lower-order units may be linked to one higher-order unit and are contained in the same data file. |
If there are different levels of units in your database the flat data file can be impractical because it may include a large number of blanks and put great demands regarding the size of the file. In addition, it may also reduce the operability and clarity with regard to differentiation of types of units of analysis. Database applications like e.g. D-base, MS Access or SQL, allow structuring your data in a hierarchical order. |
| Definition |
File types |
| The relational database is a system of several data matrices and defined associations between them. |
Different other database applications, e.g., D-base, MS Access or SQL databases, allow the structuring of your data in a hierarchical order. You may also split your data into several interrelated flat files, i.e. structure your data into a relational database, and retain the ability to use statistical software mentioned above. |
Structuring a database from a household survey
If you consider a database from a household survey, there are at least two different types of units of analysis, households and individual household members. However, you may structure such database in all three ways below:
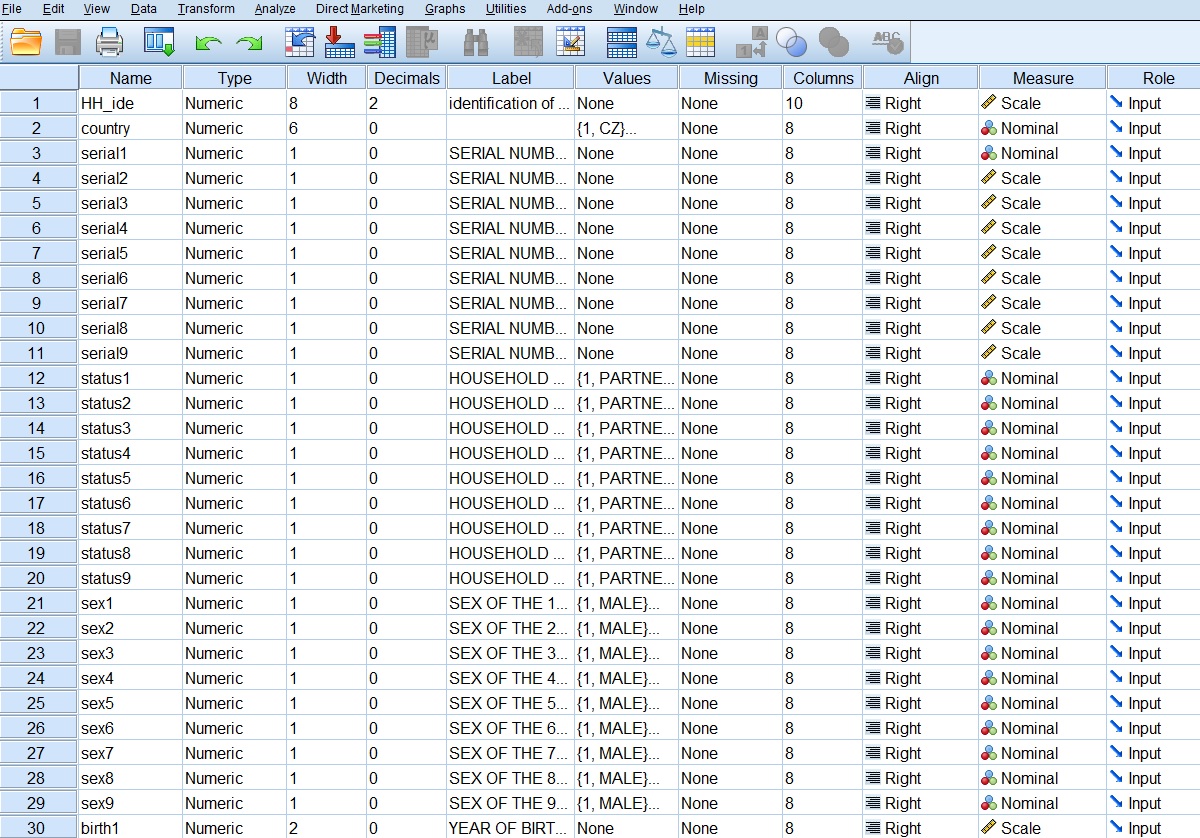
If you decide on a hierarchical structure, data on the household are recorded at one level and data on household members at another level.
You can download an example of a hierarchical file in *.sav below.
Another solution is to create a relational database. Information about household members is recorded in independent matrices that are interconnected by means of a household ID or a more complex parameter that represents not only the sharing of a household but also the type of family relationship between household members or similar. For instance, users can search for rows with equal attributes in this type of database. Relational databases may also serve as a basis for creating files adapted for individual exercises by combining information from different matrices.
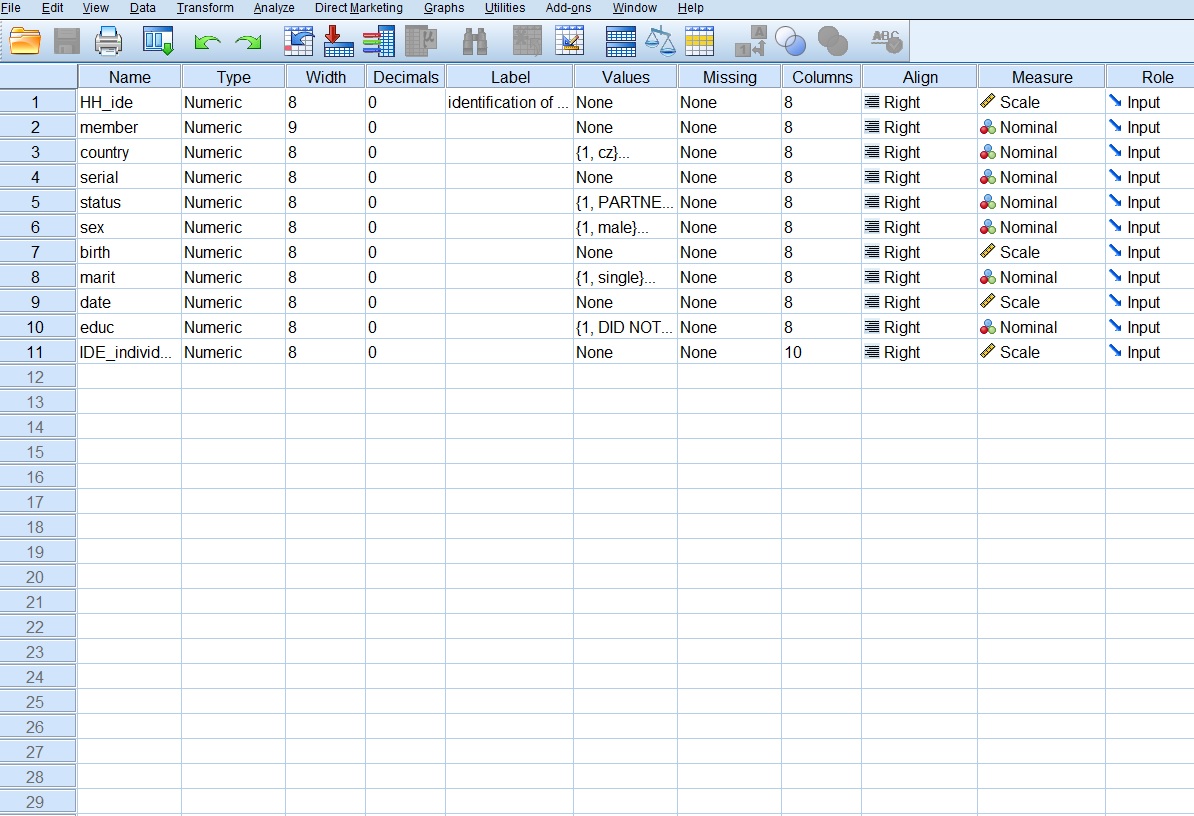
However there could be a situation where you may need to use complete household survey data in your analysis and your software requires a flat file. In this case, you can add a household ID variable and copy particular household data for each individual member of this household. This would create a set of individuals. Another possibility would be to organise records for all household members in long rows, which would create a set of households.
You can download an example of such a flat file in *.sav below.

SHARE: A complicated database of micro data on health, socio-economic status and social and family networks
The Survey of Health, Ageing, and Retirement in Europe (SHARE) is a multidisciplinary and cross-national panel database of micro data on health, socio-economic status and social and family networks. Surveys are organised bi-annually since 2004. SHARE currently covers 28 European countries and Israel. The SHARE database is easily accessible to the entire research community; data from the SHARE Waves 1 to 6 have been available since 2017.
Description
SHARE is targeted to individuals aged 50 or older and their households. The resulting database is quite complicated due to the following:
- SHARE is an international survey and its data come from different countries;
- SHARE is a panel survey repeating interviews with the same sample of households every two years, so the data come from different waves of the survey using questionnaires including both, repeated and new questions;
- A systematic process of refreshment is implemented and new households are added to the panel at each wave. That is the reason there are two types of questionnaires: the baseline questionnaire for respondents who participate in a SHARE interview for the first time and the longitudinal questionnaire for respondents who participated in SHARE before;
- There are different components of the survey with different sources of information collected under different data collection modes. The data collection modes include face-to-face interviews based on computer-assisted personal interviewing (CAPI) on household level, CAPI on individual level for different types of household members, paper and pencil (PAPI) drop-off questionnaires, so-called vignettes, i.e. questionnaires on respondents reactions to specific situations, physical tests, collection of dried blood spots (only in some countries), specific end-of-life questionnaires, interviewer observations and generated variables;
- Different types of respondents answer different parts of an interview for household: (1) family respondent, (2) financial respondent, (3) household respondent; in addition, e.g., in case of physical or cognitive limitations of dedicated respondent, it is possible to organise a 'proxy interview' with another member of the household (proxy respondent);
- The survey and its database are also structured by topics.
Unique identifiers
The features of the surveys which are described above, result in a complicated relational database.
Up to 30 different data modules are available for each wave of the survey, for each of participating countries and for databases combined across time and countries. Moreover, there are also two levels of data based on units of observation, households or individuals. Data from different modules and/or waves may be merged using the following set of unique identifiers:
- For merging data on an individual level the variable "mergeid" provides a unique and non-changing person identifier for all waves. It has the format "CC-hhhhhh-rr" (e.g., "AT-070759-01"), where CC refers to the short country code (here: "AT" for Austria), "hhhhhh" are digits to identify the household, and "rr" is the respondent identifier within each household.
- For merging data on the household level there is a set of variables hhid "w", where "w" indicates the respective wave. hhid "w" has the following format "CC-hhhhhh-S" (e.g., "AT-070759-A"), where "CC" refers to the short country code, "hhhhhh" is the household identifier, and "S" identifies possible split households, i.e., the household of a panel member who moved out of a previous household. In case of a household split there is not only an "A"-suffix but also "B", "C", etc.
In addition, there are several "Special Data Sets", e.g., interviewer survey, country-specific projects to link SHARE data with selected administrative records and 'Biomarkers' (objective health measures or a retrospective panel about working life histories of SHARELIFE respondents (SHARE Wave 3)).
For purposes of analysis, SHARE provides a very extensive set of weights (See Weighting). Which weights to use really depends on the concrete research question, i.e., the cross-sectional or longitudinal nature of the study, the waves under investigation, the unit of analysis (household or individual), and the reason for weighting sample observations (SHARE, 2017: 34).
easySHARE for training purposes
Working with the SHARE panel data is very demanding. Thus, in addition to the standard SHARE database, also a longitudinal data set "easySHARE" has been created for training purposes. It contains only selected variables merged into a single data file, making it more user-friendly. However, for deeper analysis, a standard database is necessary.
Dive in deeper?We have a subtopic prepared for you on organising variables. Here you will find tips on how to build the internal structure of quantitative data files by organising, naming and labeling variables. Alternatively, you can proceed to the section on designing file names and folder structures. |